Scene Editing as Teleoperation (SEaT)
A Case Study in 6DoF Kit Assembly
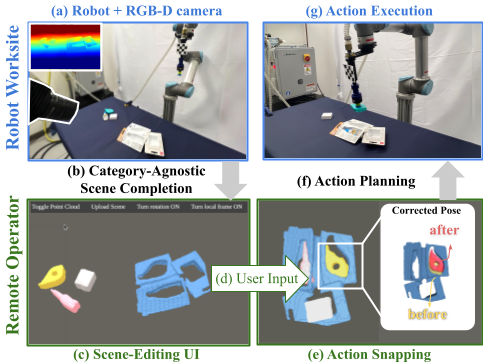
Studies in robot teleoperation have been centered around action specifications—from continuous joint control to discrete end-effector pose control. However, these “robotcentric” interfaces often require skilled operators with extensive robotics expertise. To make teleoperation accessible to nonexpert users, we propose the framework “Scene Editing as Teleoperation” (SEaT), where the key idea is to transform the traditional “robot-centric” interface into a “scene-centric” interface—instead of controlling the robot, users focus on specifying the task’s goal by manipulating digital twins of the real-world objects. As a result, a user can perform teleoperation without any expert knowledge of the robot hardware. To achieve this goal, we utilize a category-agnostic scene-completion algorithm that translates the real-world workspace (with unknown objects) into a manipulable virtual scene representation and an action-snapping algorithm that refines the user input before generating the robot’s action plan. To train the algorithms, we procedurely generated a large-scale, diverse kit-assembly dataset that contains object-kit pairs that mimic real-world object-kitting tasks. Our experiments in simulation and on a real-world system demonstrate that our framework improves both the efficiency and success rate for 6DoF kit-assembly tasks. A user study demonstrates that SEaT framework participants achieve a higher task success rate and report a lower subjective workload compared to an alternative robot-centric interface.

Paper
Latest version: arXiv:2110.04450 [cs.RO]

Code
Code and instructions to download data: Github.
Team





Technical Summary Video (with Audio)
Video Results with Unseen Real-world Kits
Results with Unseen Real-world Kits
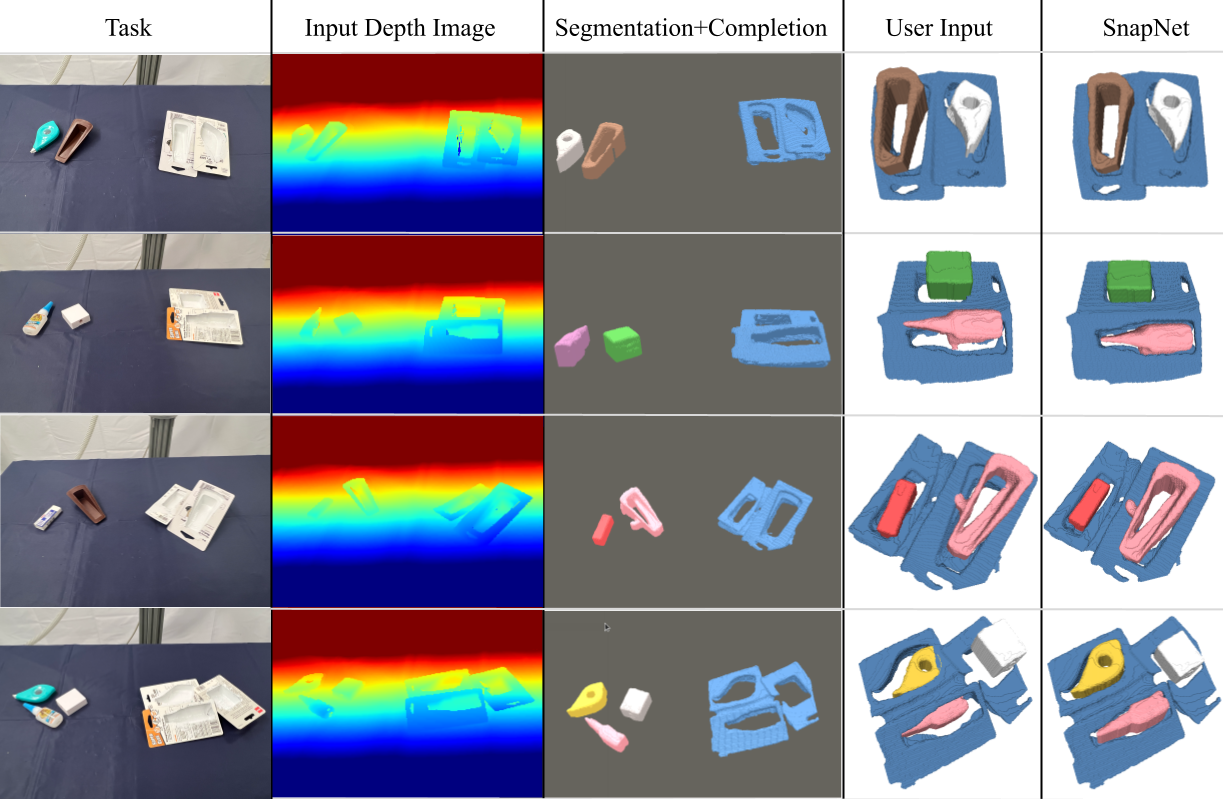
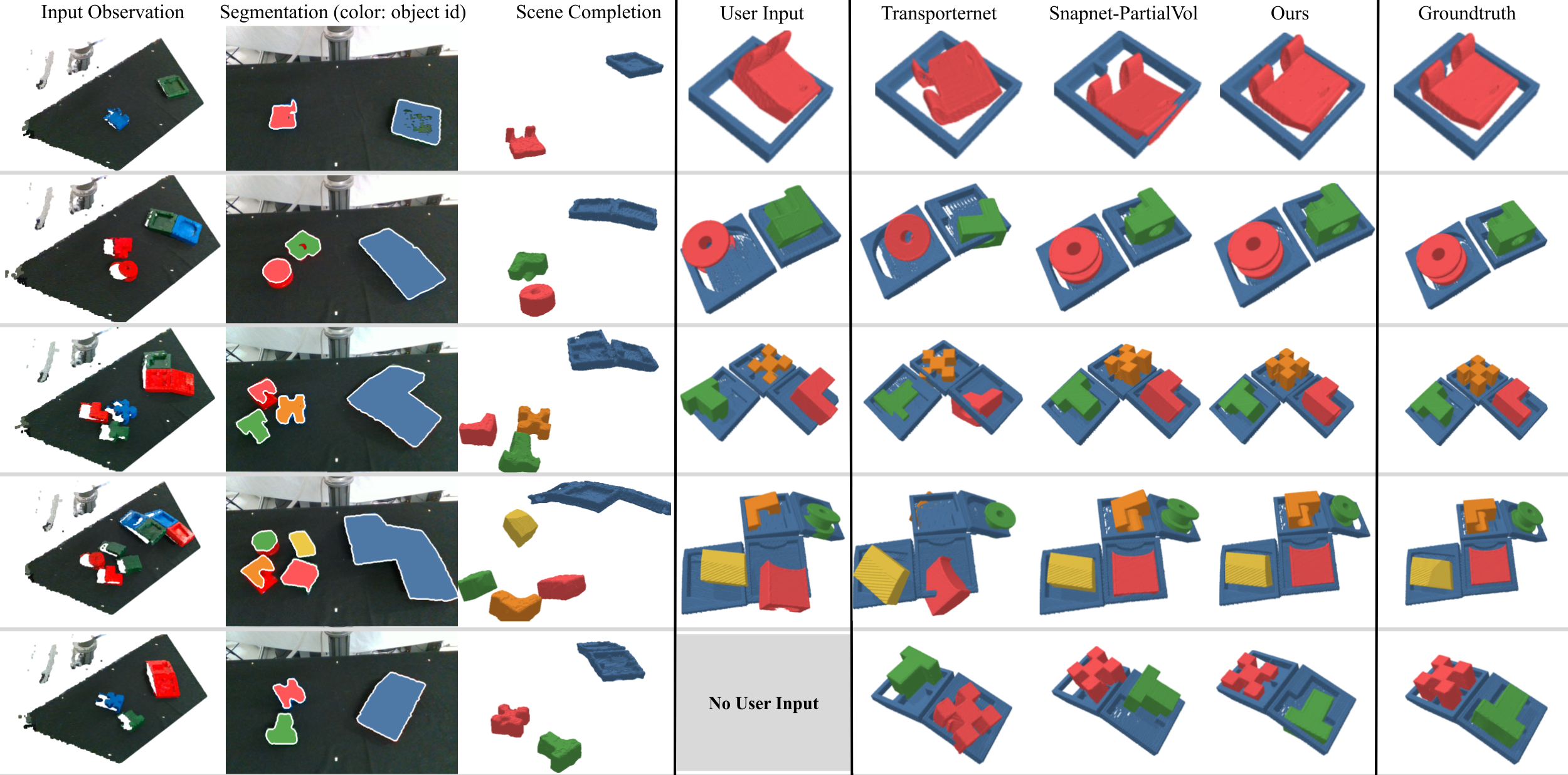
Results with Unseen 3D-printed Kits and Comparisons to Alternative Methods
User Study Analysis
 We conducted a study with 10 recruited participants and compared our system with EE-Control, a representative teleoperation interface where a user can specify 6DoF pick-and-place pose of the end-effector on the point-cloud representation of the scene. User study participants completed five trials of kit-assembly tasks with both interfaces (kit sets showed on the right), including one two-kit task as a sample trial, and two 2-kit and two 3-kit tasks for actual trials.
We conducted a study with 10 recruited participants and compared our system with EE-Control, a representative teleoperation interface where a user can specify 6DoF pick-and-place pose of the end-effector on the point-cloud representation of the scene. User study participants completed five trials of kit-assembly tasks with both interfaces (kit sets showed on the right), including one two-kit task as a sample trial, and two 2-kit and two 3-kit tasks for actual trials.
Objective Dependent Measures
We have three objective dependent measures: the success rate, the specification time (the time spent by the user on a specific interface per object), and the execution time (the total system time minus the specification per object). For the execution time, the only difference between two systems is that SEaT has additional model inference modules which take +12s per object comparing to EE-Control. For the success rate and the specification time, we perform two groups of analyses with pairwise t-tests: (1) a "group by user" analysis where we obtain a success rate and a per object specifcation time for each user, (2) and a "group by trial" analysis where we obtain a success rate and a per object specifcation time for each trial, separating 2-kit tasks and 3-kit tasks. In both groups of analyses, we find SEaT to be significantly better. In the paper, we cite the "group by user" analysis.

Subjective Dependent Measure
Our subjective dependent measure is NASA Task Load Index (NASA-TLX), which consists six dimensions including MentalDemand, PhysicalDemand, TemporalDemand, Performance, Effort, and Frustration. The user study participants reports a value ranges from 1-7 for each dimenion, where lower values indicate lower task load or better performance. The analysis below shows that the participants experienced significantly lower MentalDemand, TemporalDemand, Effort, and Frustration when using SEaT.

Grasp Pose Estimation and Trajectory Computation
We perform top-down suction based immobilizing grasp for picking up the object before executing our place primitive (Sec. IV-D in paper). A suitable picking position \(^{robot}P_{pick} \in \mathbb{R}^3\) is one which is flat and horizontal, and wide enough to contain the gripper suction cup. To do this, we first compute \(n\) points point-cloud \(PC \equiv \{p_{i} \in \mathbb{R}^{3}\}\) from the masked depth image \(MD\) (Sec. IV-A in paper) and estimate normals for each pont \(p_i\). We select the points whose vertical component is greater than \(0.9\). The selected points are then projected to \(xy\) plane to create a \(2D\) image \(K\). \(K\) is then convolved with an identity kernel of size (suction_width, suction_width) and the maximum value point is chosen as the grasp location \(^{robot}P_{pick}\) (suction_width = 4.5 cm).Acknowledgements
The authors would like to thank Zhenjia Xu, Samir Gadre, Huy Ha, Chi Cheng, Xiaolong Li, Yifan You, and Boyuan Chen for their help throughout the project. We would also thank Google for their donation of UR5 robots. This work was supported in part by the National Science Foundation under CMMI-2037101 and Amazon Research Award. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Citation
To cite this work, please use the following BibTex entry,
@inproceedings{yulong2022scene,
title={Scene Editing as Teleoperation: A Case Study in 6DoF Kit Assembly},
author={Li, Yulong, and Agrawal, Shubham, and Liu, Jen-Shuo, and Feiner, Steven, and Song, Shuran},
booktitle={2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year={2022},
organization={IEEE}
}
Contact
If you have any questions, please feel free to contact Yulong Li or Shubham Agrawal.